
FAIRness and research software
5 September 2024
FAIR-IMPACT is a three-year European project which is working to realise a FAIR European Open Science Cloud (EOSC) of data and services that are findable, accessible, interoperable and reusable. It will achieve this by supporting the implementation of FAIR-enabling practices across scientific communities and research outputs at a European, national, and international level.
The University of Edinburgh, led by the Digital Curation Centre (DCC), is one of the six core partners of the FAIR-IMPACT project. EPCC, through the Software Sustainability Institute, leads the task focusing on "FAIR metrics for research software". We are working in close collaboration with additional European partners such as INRIA (France), the University of Bremen (Germany), and DANS (the Netherlands).
FAIR principles
FAIR stands for 'Findable', 'Accessible', 'Interoperable' and 'Reusable'. The FAIR principles originated in 2016 as defined by Wilkinson et al. [4] and were originally applied to data only. They are meant to be broad recommendations and guidelines, rather than prescriptive rules, and are designed to help the community make existing data easier to use in the widest sense.
These principles can and have been extended beyond data to other digital objects, such as research software, where they are known as the "FAIR principles for Research Software version 1.0"(FAIR4RS Principles v1.0). Users should be aware that a high level of FAIRness for any research software does not guarantee the software's quality itself.
Assessment
So, how can users assess the FAIRness of their software and why should they do this?
First, for the software research community to assess the FAIRness of its software, the more abstract principles have to be translated into practical tests. These tests can either be self-guided assessments, which are offered by various websites, or automated assessment tools. Automated tools are generally more consistent, objective and quicker in assessing FAIRness. To automate the assessment, every principle needs to be presented by one or more criteria, which we call metrics, which then will be turned into an actual test that will be implemented in an automated assessment tool (see figure 1).
Figure 1: Process from principles to metrics, to tests and implementations.
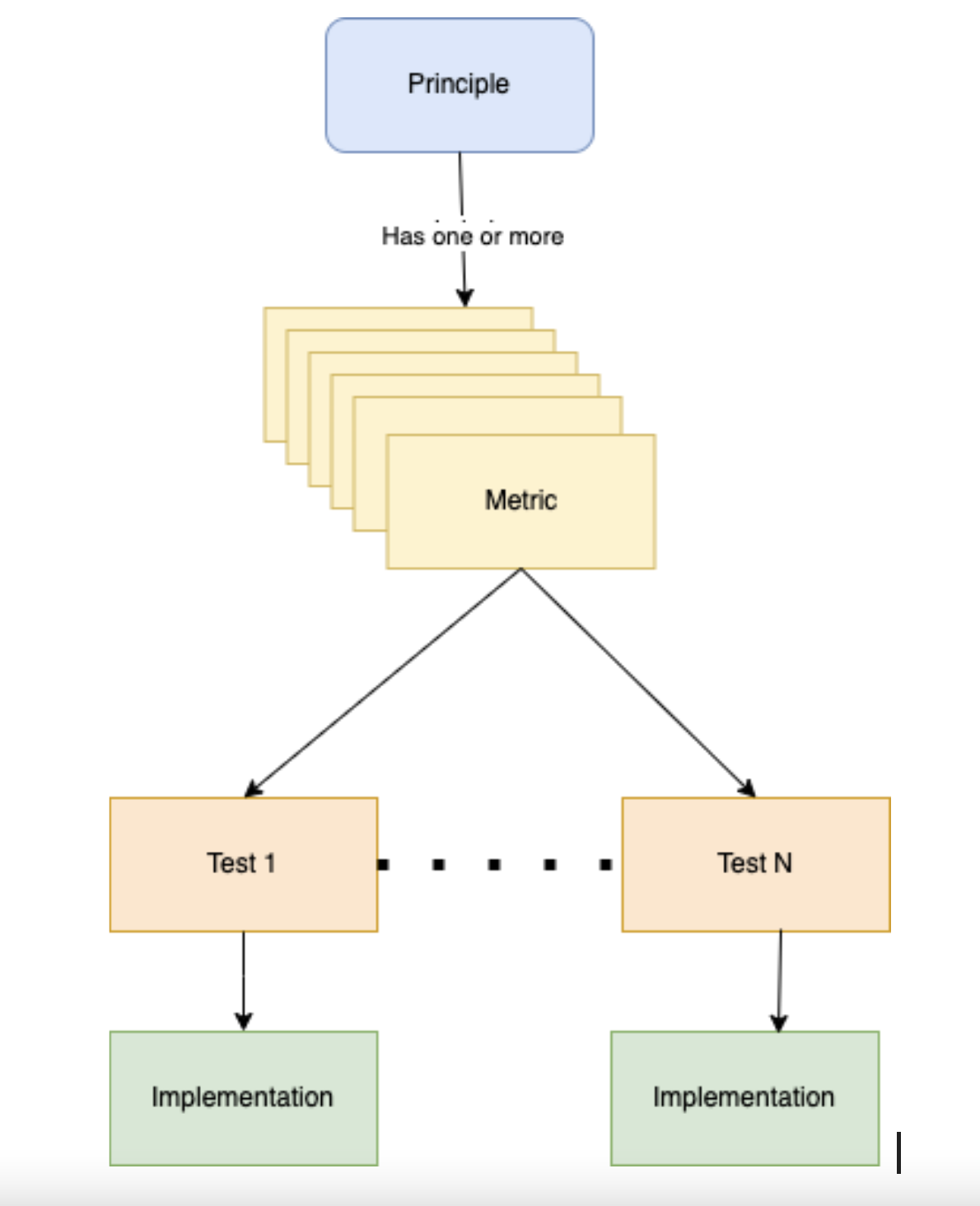
When we started working on the project, we examined three automated tools [1], which focused on the FAIRness of data, not research software, so they did not explicitly assess the FAIR4RS principles, though many principles are shared between FAIR data and software. There was also a lack of metrics for FAIR software.
In addition, we examined a fourth tool, which was the only one addressing the FAIRness of software, but it did not use the FAIR4RS principles, relying instead on five generic principles that can be mapped to them.
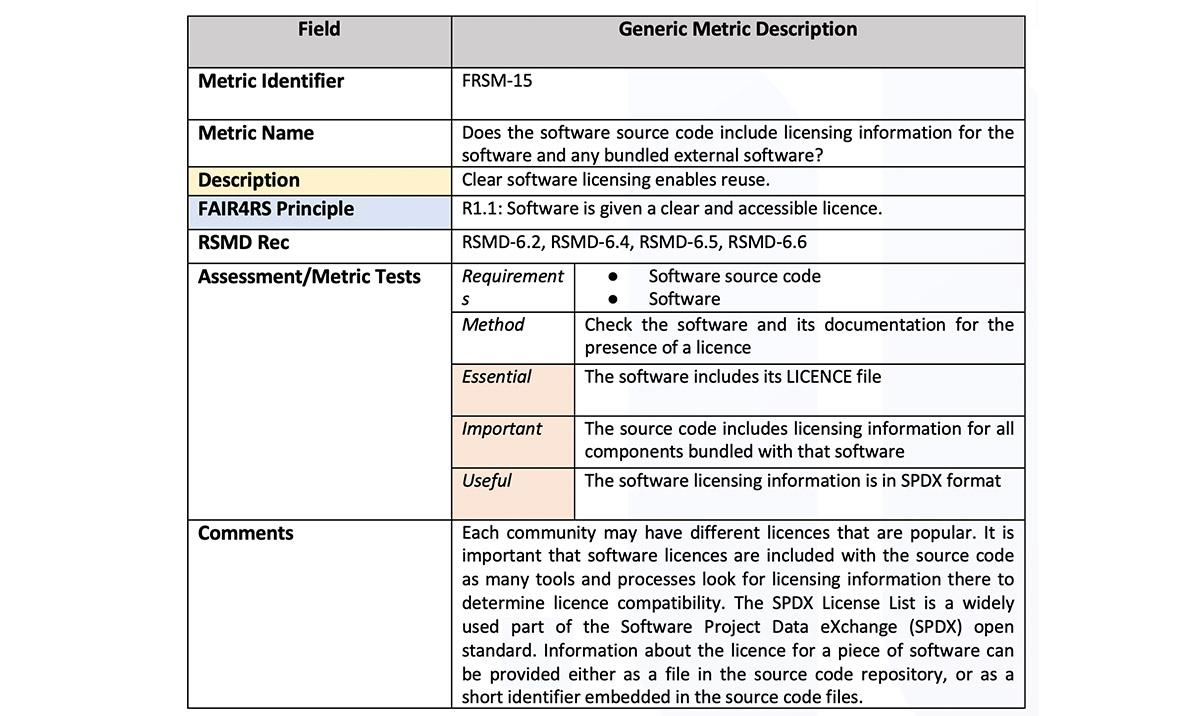
We developed 17 metrics [2] in FAIR-IMPACT, which build on the outputs of past working groups and existing guidelines related to FAIRness (see example in figure 2). There is an expectation that while the metrics and assessment methods will remain the same, the criteria for each compliance level (like 'essential', 'important', 'useful') will change as adoption of the FAIR principles increases and infrastructure, tools and guidance improve. We developed both the most general, domain-agnostic metrics as well as using the Social Sciences as an exemplar for a more specific implementation based on their characteristic community standards.
Figure 2: Generic metric description example for metric 'FRSM-15'.
Evaluation of tools
The focus of our evaluation [1] of existing automated FAIR assessment tools was to determine whether these tools could be used out of the box to test compliance with the FAIR4RS principles and whether they could be extended to specifically include them in a domain-specific context.
So far we have been concentrating on github repositories for all our work. We then use the automated assessment tool for data, F-UJI, extending its usage to research software and the FAIR4RS principles. We chose F-UJI because it is the most actively developed of the automated tools we have investigated, and the developers are part of the FAIR-IMPACT project.
Proof of concept
For proof of concept, we fully implemented two of the FAIR4RS metrics from [2] as well as providing skeletons for many of the other metrics [3]. These tests were discipline-agnostic but additionally, we implemented discipline-specific versions based on the metrics versions as defined by CESSDA (Consortium of European Social Science Archives) in [2]. The latter tend to be more specific, which makes them easier to assess automatically.
Improving the FAIRness of research software, or any other digital object, makes it easier for a wider community to engage with it by increasing how findable, accessible, interoperable and reusable it is. Although the FAIR principles have no normative requirements (ie users are not obliged to adhere to them), the desire to make autonomous assessment possible may normalise user behaviour to improve assessment results.
Limitations
There are limitations with automated FAIRness assessment tools that users should be aware of. An automated testing framework will, by necessity, need to make assumptions in order to simplify the testing.
It is more useful for the end user to learn how they can improve the FAIRness of their repositories to score more highly than to be told only that tests have been failed. Current tools lack this useful characteristic. For this reason, tooling also needs to be transparent about how it is making its assessment, and what it does and does not check for.
FAIRness faces other challenges if it is to be successful in the future. There is the need to sustain existing FAIR assessment tools, their continuous development and improvement, and the developers' continuing interest. The existing frameworks need to be easily extensible to allow for further implementations of tests or even new metrics. To ensure consistency, domain-agnostic tests must not diverge across different toolings or science communities.
Next steps
During the remaining stages of the task we will mainly focus on dissemination of the work described above. We are currently also leading a series of three FAIR-IMPACT OpenCall workshops on "Assessment and FAIRness of research software" with eleven participants from across Europe and across a variety of science communities. The groups will apply our extended version of the F-UJI tool to their specific use cases and we hope to gain lots of insights from their experience with the tool and the metrics to help us improve our work in the future.
References
[1] Antonioletti, M., Wood, C., Chue Hong, N., Breitmoser, E., Moraw, K., & Verburg, M. (2024).
Comparison of tools for automated FAIR software assessment (1.0). https://doi.org/10.5281/zenodo.13268685
[2] Chue Hong, N., Breitmoser, E., Antonioletti, M., Davidson, J., Garijo, D., Gonzalez-Beltran, A., Gruenpeter, M., Huber, R., Jonquet, C., Priddy, M., Shepeherdson, J., Verburg, M.,& Wood, C. (2023, October 27).D5.2-Metrics for automated FAIR software assessment in a disciplinary context.
https://zenodo.org/records/10047401
[3] Moraw, K., Antonioletti, M., Breitmoser,E., Chue Hong, N., Priddy, M. (2024). M5.6 - Practical tests for automated FAIR software assessment in a disciplinary context.
https://zenodo.org/doi/10.5281/zenodo.10890042
[4] Wilkinson, M., Dumontier, M., Aalbersberg, I. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data 3, 160018 (2016). https://doi.org/10.1038/sdata.2016.18
